Land cover conflation. Unsolved issues and further ideas
This post continues where the previous one left off.
After some time spent on processing and importing land cover data, I have several ideas on how to further improve and streamline both the import process and in general work with land cover features in JOSM.
Suggested tools to help with land cover data
Certain typical tasks arise over and over again when one works with polygons meant to represent land cover, regardless of whether they are imported or manually traced. At the moment there are no adequate tools in JOSM to assist with such tasks.
The trick here is not trying to find an exact geometric solution to the tasks at hand, but rather imitate what a human would reasonably do to finish such a task. And a human would cut corners, allow some inexactness traded in for speed of completion.
Floodfill tool
A common task is to fill a gap between two or several polygons. An example would be to map a new farm field situated between several forests or clammed between several intersecting road segments. Currently one has to carefully trace a new way along the existing borders, either reusing nodes or leaving a small gap between the new ways and adjacent ones.
The idea here is similar to pouring a bucket of paint into the middle of the empty area and then letting it spread out naturally to fill the empty area. The paint will then spread out until it hits borders, or until it runs out of paint.
The same approach can be implemented in a tool that starts from a single node (or rather, from a tiny closed way) which then grows in all directions. Its growth is stopped when a segment of the new way hits a boundary in a form of an existing way. Optionally, the new way can then snap to existing way there.
It sounds simple, but it will require some clever implementation to be robust, fast and reliable. I can already see a couple of implementation details that will require some attention during the implementation.
-
The resulting polygon does not have to fill precisely the intended area. It is not bound to share all its boundary segments with surrounding features, or reuse all of their nodes. Surely, some nodes and segments may be shared, but solutions that leave a small configurable gap between the new polygon and old polygons are also acceptable.
-
The resulting polygon should treat itself as a boundary as well. It may happen that a resulting figure has holes in it, and a new polygon should become a multipolygon. The simplest alternative is to keep it as a polygon with thin “bridges” in it, almost wrapping around the inner holes.
-
Surrounding land cover features are not guaranteed to create a closed perimeter around the empty area one wants to map. There is a risk that the contents of the new area will leak outside through gaps it founds between these surrounding features. To prevent uncontrolled spreading of the new way through such leaks two strategies may be applied. Firstly, total area allowed to be covered by the floodfill process should have a hard limit. Secondly, spreading through such holes can be detected by giving new nodes a non-zero buffer diameter. This basically makes them thick, and they won’t be able to squeeze through gaps smaller than a predetermined value.
Polygon breaking tool
There are many situations when splitting a closed way that either intersects itself or overlaps with another one makes sense. Possible uses of such functionality include:
-
Fixing self-intersections of small loops left after simplification or coordinate transformations of polygons.
-
Assuring new polygons have a nice single common border with old ones by cutting them in two by that boundary and then removing the smallest part as noise.
This is similar to what v.clean [1] does with options tool=break and tool=bpol.
Another useful addition is to clean up zero angles in polygons, identically to
what tool=rmsa does. These are always artifacts not worth keeping and as such
it should be possible to remove them.
Smart and configurable tool to snap nodes
Having nice common borders between land cover features without any under- or overshoot is a hard task requiring a lot of manual labor.
To drag or replace nodes to make a common border is called “snapping” them to new place.
Current embedded JOSM-tools (“N” and “J” buttons) lack configurability and cannot be used at scale, although they are very useful to patch something up.
The main problem with snapping is that it can destroy geometry quite significantly if done without measure.
To make decisions which nodes to move and which to keep, a threshold distance value is used. However, the nodes to be snapped are usually already organized in ways, and preserving sanity in these ways after some of their nodes have been moved is a huge task.
There are often two situations/issues: 1) to snap a node when there are multiple alternatives within a threshold distance, and 2) in which order to snap several nodes already placed on a way.
If several nodes from the same source way are snapped to different ways in its vicinity, the result is often a mess of self-intersecting ways.
Even if the same target way to snap is chosen for several nodes, if the order in which they are included into it is wrong, the result has zero-angled segments and annoying overlappings with destination ways within a narrow threshold area around them.
What I think is needed is to think about the problem as an optimization task. An algorithm may iterate over small movements of individual source nodes which are moved according to “the force field” or “a potential” function defined by positions of destination ways. Source nodes which are far enough from destination segments do not experience any incentive to move around and are mostly still. Nodes closer to the threshold distance are attracted to destination ways, and eventually get placed on them. To prevent nodes becoming in a wrong order only one node per step is allowed to be included into a destination way, which can only be done unambiguously. In next iterations that node is treated as if it always was there, and incoming snapped nodes are ordered automatically correctly relative to it (XXX is it true? can I prove it? are there couterexamples to that?)
To prevent source segments to overlap with destination segments the force potential should repulse the source segments from destination nodes. This way, source nodes are attracted to destination
As it was pointed out earlier, we are not looking for a 100% correct solution but for a one that is good enough without being too destructive. The bad part is that this algorithm is more complex than simple snapping that could be done in linear time. A number of iterations to achieve a stable result may be hard to guess in each case.
Scanaerial integration into JOSM. Take into account existing object boundaries
Scanaerial [2] is a tool to help with tracing of aerial images. It is espacially effective for water surfaces (as they have simpler textures than e.g. forests).
The problem is, it is an external program written in Python. Amongst many problems that this brings are: less than possible speed, no progress indication, awkward configuration of aerial imagery to use.
Inclusion of the same functionality into JOSM directly as a Java plugin would allow the tool to have a better interface and provide smoother user experience. It could use all imagery that is present as JOSM layers.
Another improvement is that it could be improved to stop at boundaries where there are already traced objects, by e.g. using them as a mask for raster. That would save a lot of time conflating results of tracing into the whole picture.
Not yet solved problems of traced data quality
This section discusses not yet solved problems in the import data I’ve worked with. It was required to manually edit their consequences, which was the limiting factor for import. Thus they are very much welcome to be solved mechanically whenever it is possible.
Nice parallel borders along roads
Compare the following two pictures. Before cleaning import forests along a road:
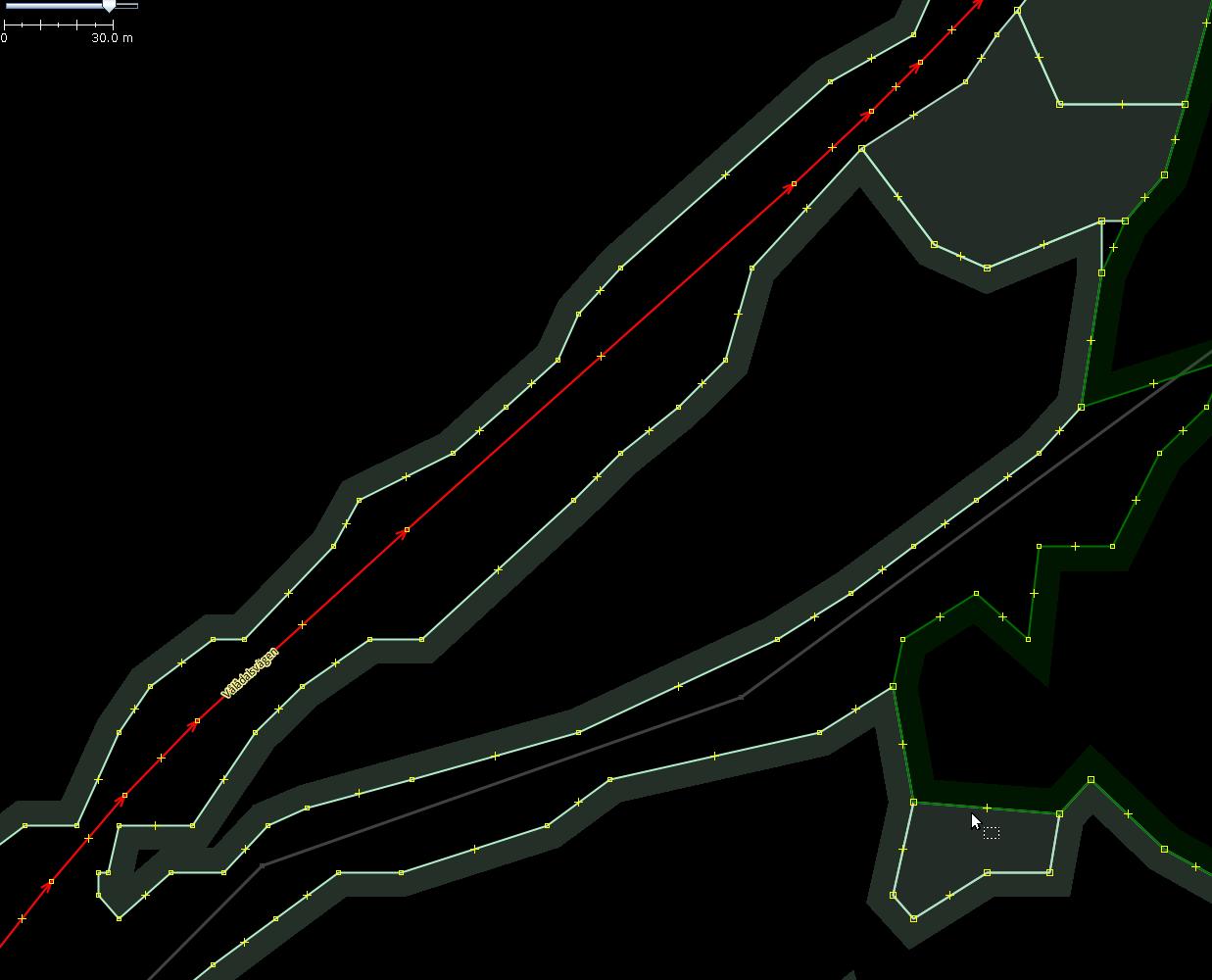
After manual cleaning of nodes.
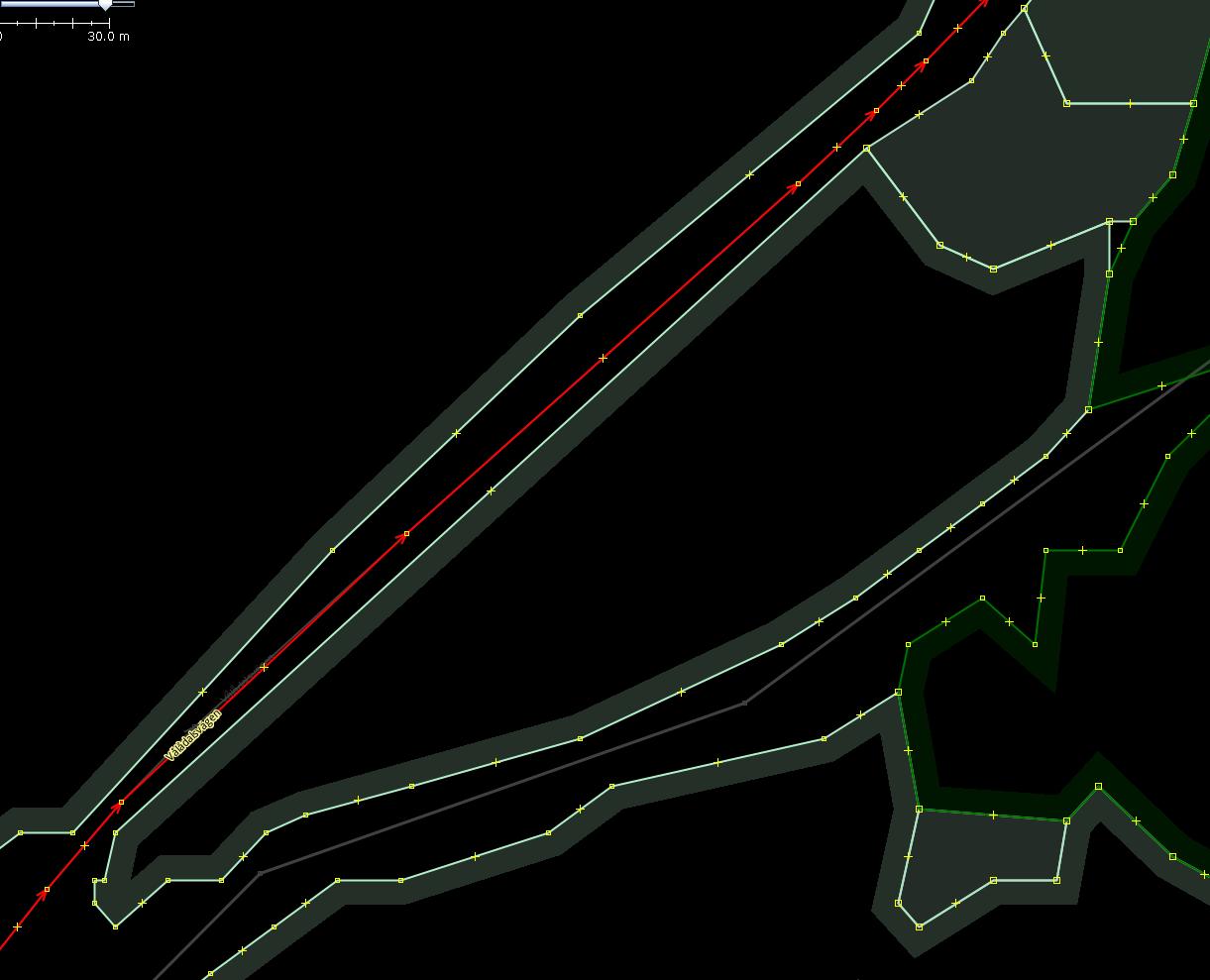
Usually humans find the second variant to be preferable as it has less nodes and less clutter.
The task is almost equivalent to snapping nodes to an “invisible” buffer polygon created around the road. If all source nodes are placed on the buffer boundary, resulting forest borders would be parallel to the road in the middle.
Almost road channels in multipolygons
A road can run through a massive of a forest, farmyard or similar land cover. Alternatively, it can be placed completely outside of any land cover, effectively cutting it in halves. The road then has its own “channel” in which it runs.
The worst case is when one has a mixture of these strategies. A road that runs outside the forest but then jumping into a short chunk of it and then emerging back from it is confusing. See the picture for explanation.

Here, outer and inner ways of the surrounding multipolygon create “almost” a channel for the road. To properly remove the “plug” in this channel requires a huge amount of work: to split the outer way in two, to split the inner way in two and change its role to outer, then sew matching parts of these halves to obtain two outer ways placed on both sides of the road.
Deciding what to do with old data of lower resolution
This is kind of self-explanatory.
As we get more and more highly detailed aerial pictures and more and more advanced remote sensing and tracing software, it is often obvious during an import when existing data is of lower resolution than the data that could have been imported in its place instead. But, to play it safe, the old data is considered to be “golden”, and new fine features get mangled at borders that contact old coarse features.
In the case of lakes, many of them were present on the map, but badly traced. If we were to import lakes as well, it would be preferrable to replace those old ones with coarse boundaries with new ones. But how to reliably decide?
Is it possible to measure resolution of vector objects?

Final thoughts and ideas
A few notes to self to try before importing the next huge chunk of data. Or, to do as a completely separate imports.
-
Create a workflow to create raster mask layers from OSM XML by converting it to SHP and then to GeoTiff. Using QGIS and Geofablik’s exports is error prone as there are multiple files to combine and they have weird category mappings.
-
Import of new short ways as single nodes when resolution is not enough. Individual houses are typically represented as a pixel in the input raster, or four nodes of 10×10 meters square in its vectorized form. For really remote buildings outside of any residential areas, it is possible to at least record their position as a node.
-
Replacing geometry of ways with finer geometry. If there is a way to measure a “resolution” of a vector feature (fractal dimension metrics?), then two features whose centroids are close enough can be compared. Assuming that both features represent the same physical object, it can then be decided whether to replace old geometry with a new one.
-
So far I was concerned with the goal of filling in the empty places. Defining and implementing a strategy for updating land cover is yet another topic to explore. The key here is to reliably decide when two features from old and new datasets represent the same object, and which representation is worth keeping. An techinique to cut holes in existing multipolygons will become critical to have to in order to e.g. implement a scenario when a section of a forest got burned down and should be excluded from the old multipolygon. Differential pixel comparison of new and old import data might become handy to find all places with “diffs” and act only on them. The key here is to bring raster inputs to comparable states (identical coordinate systems, spatial extents, pixel resolutions and land cover classifications).
-
Generate import vector datasets of different “resolution” or “detaileness”. That is, prodice a family of parameterized datasets which have different aspects of their generation adjusted to one or another side. E.g., have a new layer that only has objects larger than a predetermined value; or have only data for forests; or apply different aggressiveness of smoothing algorithms. Typically, the “resolution” of new data is dictated by existing data density for the tile. It does not make sense to add multitude of fine details to a tile that was coarsely outlined, without essentially redoing it from scratch. However, there should be just a few of such datasets per a tile though. Otherwise one would spend too much time choosing from them and comparing them between each other instead of integrating them into the map.
-
Use local “rubber band stretch” transformations for the vector data when adjusting positions of individual nodes in respect to positions of existing nodes. Just as the pioneers in the map conflation did. The potential function idea outlined earlier kind of builds on the ability to stretch things without introducing new topological errors to human’s dismay.
-
Reduce number of inner polygons in multipolygons, leaving only the biggest ones (e.g. more than 5% of the outer way area). We have too many fine details, but which of them to keep?
-
Try using
ogr2osm[3] instead of my owngml2osm.py.
Links
- https://grass.osgeo.org/grass77/manuals/v.clean.html
- https://wiki.openstreetmap.org/wiki/JOSM/Plugins/Scanaerial
- https://wiki.openstreetmap.org/wiki/Ogr2osm